昨今の品質不正問題を見るに、個別の事例における真因ではないものの品質管理の初歩的な知見が適切に教育されていないのではないかと疑うような事例が多々見受けられます。
特に多いのが、その場での試験に合格すればよいとした、量産でのばらつきを考慮していないような事例です。
現実にはまったく同じものが生産できることなどなく、生産品には必ずばらつきが生じます。そういったばらつきを考慮した信頼性設計をしていれば数値を書き換えたり供試品に手を加えたりするような不正をする必要なんてありません。
品質管理の大家であるトヨタグループですら誤魔化しのための数値書き換えやデータ選別に類する不正が行われていたことは、正直理解に苦しみます。
よって今回は趣向を変えて、製造業の技術屋が知っておくべき品質管理に関する初歩的な事柄を解説しましょう。以前に私が技術屋1年生の若者に部内研修を行うため作った情報をまとめていきます。
初学者向けなので内容は簡単です。基礎の部分であり教科書で言えば第一章程度の内容です。また、あまり厳密性はありません。あくまで初学者向けです。
- 測定の誤差・不確かさ
- 母集団と標本
- 平均
- 分散
- 標準偏差
- 平均・分散・標準偏差のまとめ
- 正規分布
- 良品率(不良率)の例題
- 工程能力指数
- 結言
- 補足:シックス・シグマ
- 補足:統計による品質管理の歴史
- 補足:母分散と不偏標本分散の不偏性の証明
- 余談:正規分布と偏差値
測定の誤差・不確かさ
測定値には必ず誤差および不確かさが含まれる。
誤差には次のような種類がある。
【系統誤差】
測定器の器差や温度、測定方法の癖など特定の原因によって測定値が偏る誤差。
【偶然誤差】
ほこりや異物の付着など、偶然によって発生する誤差。
【過失誤差】
測定者の経験不足や誤操作による誤差。
これらを考慮して測定結果を補正・分析するには統計的手法への理解が必須となる。
補足として、過去の知見では測定値と真値の差である誤差を正規分布等に従って分析していたが、実際のところ真値を把握することはできない。よって現在ではどの程度その測定値が疑わしいかを「区間」と「信頼水準」といった概念を用いて表す。
ただし今回は初歩的な学習として、正規分布による古典的な分析を解説する。
母集団と標本
本来知りたいと思っているデータの集合のことを「母集団」と呼ぶ。
多くの場合、母集団は非常に大きく、また変化していくものであり、それらを全て測定することはできない。そのため母集団から抽出した一部のデータ「標本」を用いてその母集団の特性を統計的に解析することを行う。

この「標本」から「母集団」を推定することが推計統計学の基本となる。
平均
平均には様々な種類があるが、一般的に用いられるのは算術平均(相加平均)である。
![]()
標本空間が母集団そのものであればAを母平均、統計標本ならばAを標本平均と呼ぶ。
補足として、算術平均は標本空間の代表値の一つではあるが、それ単体で説明することはできないことを留意しなければいけない。
標本が正規分布であれば平均と分散(または標準偏差)が必要であり、正規分布からのずれを知るためには尖度や歪度といった値が必要となる。
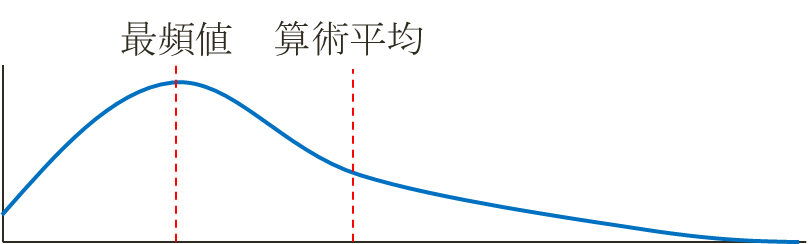
正規分布から著しく外れる場合、より頑健な中央値や最頻値を用いる。
年収の分布を例とすると、グラフは必然的に正規分布から大きく外れる。このような場合での大多数の実感に近い真ん中の値は、算術平均ではなく中央値や最頻値になる。
分散
分散とは標本が標本平均からどれだけ散らばっているかを示す指標である。
![]()
各標本データと算術平均の差を二乗して合計した後、データ数nで割った値を標本分散という。二乗するのは非負の値として取り扱うため。
実際には測定した標本には偏りがあると仮定して推定量の計算を行う。そのため標本分散ではなく不偏標本分散を用いることが一般的である。
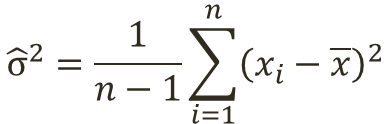
nではなくn-1にすることで期待値が母分散に等しくなる推定量を得られることの証明は長くなるため補足に記述する。
標準偏差
分散によって標本のちらばり具合を数値化することはできるが、二乗によって次元が異なっていることから数値の取り扱いが難しい。
そのため、分散の平方根を取り元のデータや平均値と同じ次元にすることで数値を取り扱いやすくすることが一般的である。
この分散の平方根を標準偏差という。
以下は不偏分散の標準偏差であり、標本標準偏差とも呼ぶ。
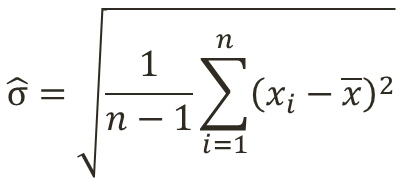
補足として、母集団と標本のどちらを取り扱うかによって平均や分散も異なる記号や表現を用いるが、これは標本に偏りがあることを想定しているためである。
推計統計学では「標本」から「母集団」の特性を推定することが目的であることから、主題として取り扱う数値は母平均・母分散となる。よって理論上や実務上において標本から計算した標本平均と標本分散をそのまま用いてはいけない。不偏推定量を用いることが一般的である。
無作為標本から推定できる平均の不偏推定量は[標本平均=母平均]であり、また分散の不偏推定量は[不偏標本分散=母分散]となる。(標本分散ではないことに注意)
平均・分散・標準偏差のまとめ
以上を簡単にまとめて簡易的に図示する。
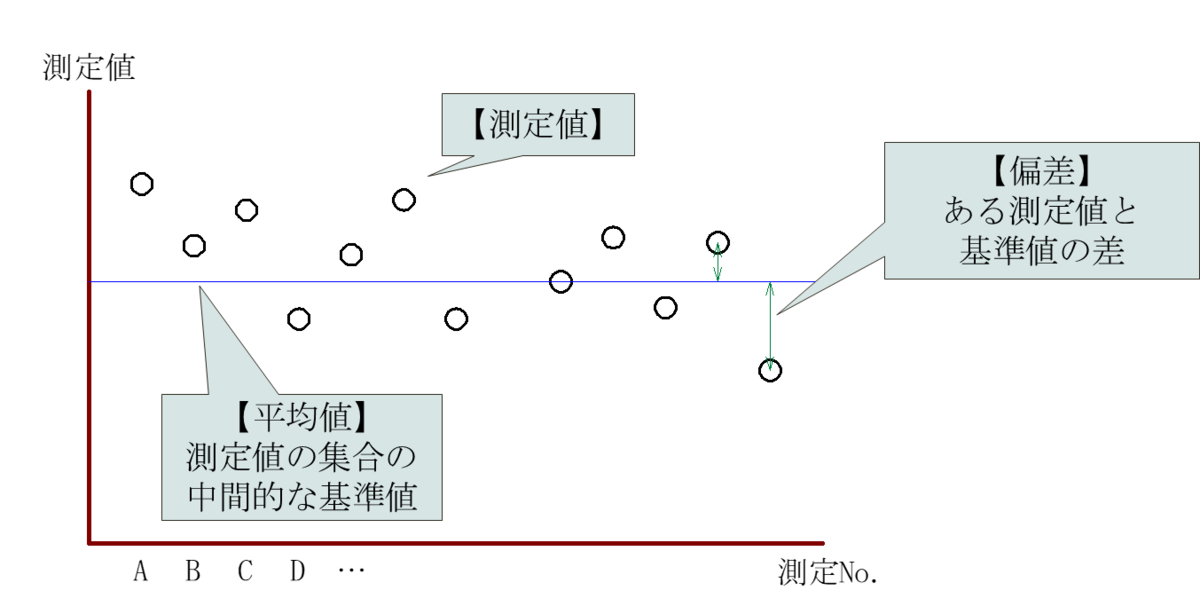
この偏差を使って複数の測定値のばらつきを数値化する際、偏差のままではプラスとマイナスの値になるためまとめにくい。

よって偏差を二乗することで扱いやすくしている。
ただし二乗すると単位が変わり他の数値と一緒に扱えなくなるため、実際の分析では平方根で分散の単位を元に戻した標準偏差を用いる。

正規分布
正規分布(ガウス分布)とは、平均値の付近に集積するようなデータの分布を表した連続的な変数に関する確率分布である。
中心極限定理により、多くの場合どのような母集団から標本を抽出するにしても標本サイズが大きくなるにつれて標本平均の分布は正規分布に近似する。そのため正規分布は様々な場面での現象を簡単に表すモデルとして用いられている。
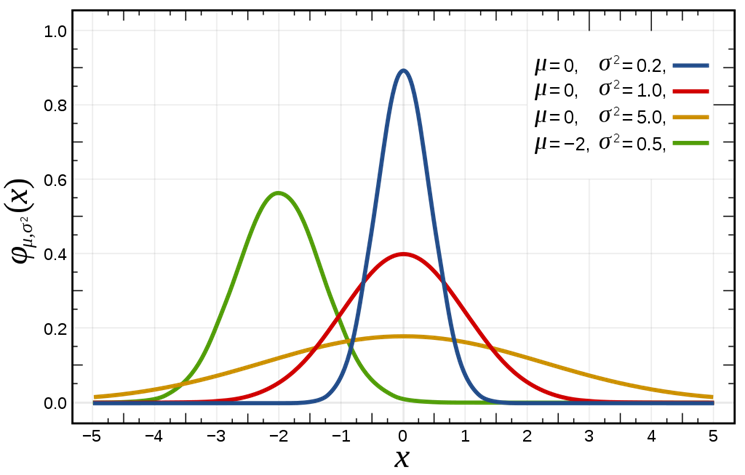
正規分布の確率密度関数f(x)は次の形で与えられる。
![]()
特に平均が0、分散が1のとき、この分布N(0,1)は標準正規分布と呼ばれる。
標準正規分布の確率密度関数は次の形となる。
![]()
全ての正規分布は標準正規分布に変換することができる。(標準化)
正規分布は確率の分布を表しており、当然ながら統計的な確率計算の処理に用いる。
どのような正規分布でも確率密度関数から個別条件での確率を計算することはできるが、計算量が膨大となることから多くの場合は標準正規分布へと標準化を行い標準正規分布表から確率を求めることが一般的である。
標準正規分布の累積確率は確率密度関数を積分することで計算できる。
製造業での実務上では主に良品率(又は不良率)を推定するのに用いられる。
すなわち、ある部品のロットから標本サンプルを抜き出して測定した結果の平均と標準偏差から、そのロットが規格幅を満足できる確率(又は規格から外れる確率)がどの程度かを推定することができる。
以下の図であれば、この部品が規格を満足する確率は約99.7%となる。(規格を外れて不良品となるのは0.3%)
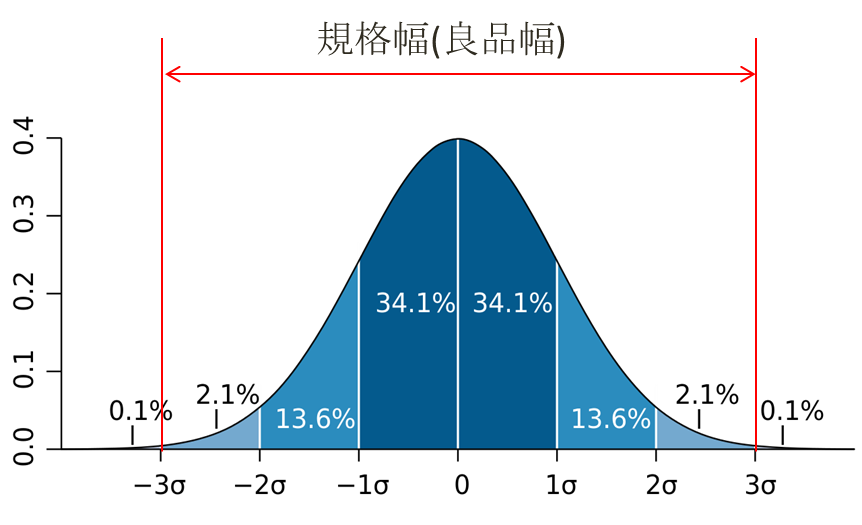
各標準偏差σごとに累積確率を計算した値は下表のようになる。
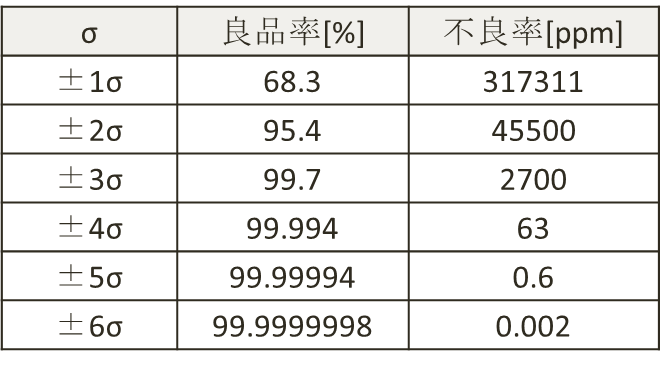
一般に、大量生産品の量産能力としては±4σが適正とされるが、製品に要求される品質や用途によってはそれ以上を求めることもある。
良品率(不良率)の例題
あるロットから無作為に10個の部品を標本として抜き取り、寸法Aの箇所を測定したとする。この寸法Aが規格10±0.1mmを満足しない確率はどの程度となるか。
※10個は少ないが、適正抜き取り数については長くなるので割愛。
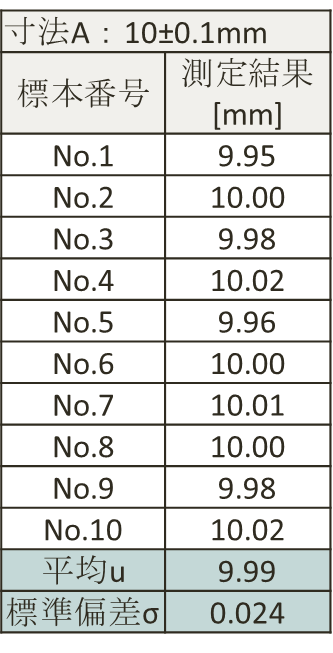
【解説】
平均uは規格幅下限寄り。
平均u-x * 標準偏差σ=規格幅下限
(9.99-0.024x=9.9 x=3.75)
つまり、規格幅に収まるのは3.75σである。
3.75σの累積確率より良品率は99.98%となることから、不良率は0.02%(200ppm)となる。
工程能力指数
累積確率を都度計算するのは手間が掛かる。
代わりに工程能力指数という指標を用いることによって、単一指標で定量的に評価をすることができる。
前提としてその工程が管理状態かつ安定した状態であることが必要であり、主に既存部品の量産安定性評価や既設工程の安全性評価に用いられる。
工程能力指数Cpは次式で表す。
![]()
規格幅と6σの商が1となる。
つまり正規分布の累積確率における±3σ(6σ)を基準1とした指標である。
Cpは平均値が調節可能で規格幅の中心とできる場合にのみ用いることができる。
平均値が規格中心から外れる場合はCpkを用いる。
![]()
過大評価とならないよう、平均値が上下限のどちらかに寄っていた場合に厳しいほうの数値を適用するような計算式となっている。
Cpの最小値がどの程度許容されるか、受け入れ可能なCpをいくつに設定するかは産業分野の違いやどのような工程であるかによって異なる。具体的な数値は都度検討する必要があるが、一般論として全米自動車産業協会(AIAG)が出版している『生産部品承認プロセス』では、
Cp>1.67:承認基準に達している
Cp<1.33:承認基準に達していない
としている。
各σとCpの対応は以下となる。
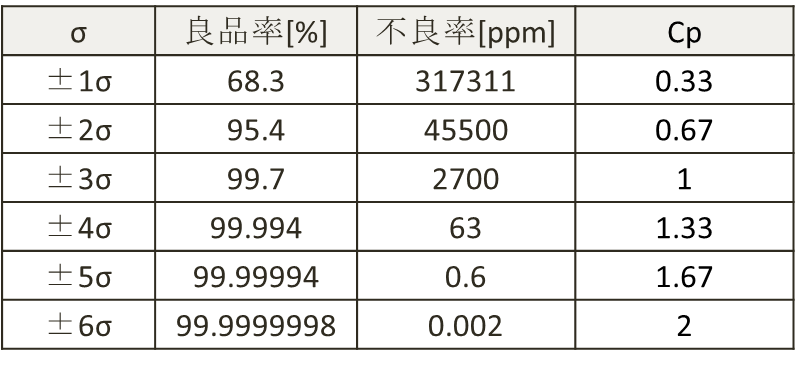
すなわちAIAGは±4σを承認基準の下限、±5σ以上を推奨としている。
補足として、Cpは高ければ高いほど良いというわけではない。
過剰な検査や精度は生産コストに跳ね返ってくる。
一般に、2.5以上(±7.5σ以上)は無駄とされる。
結言
つまるところ、統計手法を用いて確率的に問題がない設計をすること。
そうすればデータを書き換えたり下駄を履かせたりといった「確実に試験を合格できるよう施す類の不正」をする必要すらない。
補足:シックス・シグマ
シックス・シグマという品質管理手法がある。
これはアメリカのモトローラが開発した手法で、「100万回の作業を実施しても不良品の発生率を3.4回に抑える」ことをスローガンとしている。
勘違いしやすい名称ではあるが、統計的な6σとスローガンの確率は異なる数値である。シックス・シグマにおける3.4ppmの不良率は4.5σに相当する。
一般的な定説として、平均値自体が1.5σほど変動することを考慮して4.5σ+1.5σ=6σ、つまり短期的な標本測定において6σ(0.002ppm)を達成していれば長期的に4.5σ(3.4ppm)を達成することができる、とした理論である。
補足:統計による品質管理の歴史
ここまで紹介してきた手法は1980年代までに確立された、いわば古典である。
品質管理や工程管理は常に進化を続けており、企業が競争に勝ち残るためには最新の手法を導入し続けなければならない。
当然だが、新しいことだけ学べばよいというわけでもない。古典は前提知識として知っている必要がある。
補足:母分散と不偏標本分散の不偏性の証明
母分散は一般に未知数である。
標本分散は次式で計算する。
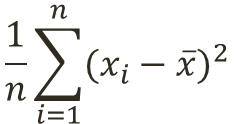
不偏標本分散は標本分散をn/(n-1)倍したものであり、
![]()
「不偏標本分散は分散の自由度がn-1になるためn-1で除算する」という説明もできるが、自由度ではなく数式で説明することも可能。
つまり不偏標本分散を計算した結果の期待値が母分散の(n-1)倍になることを証明すればよい。
補足として、不偏標本分散は標本平均を自由に決められないためその分自由度を-1している、という理解でも問題ない。
解説用に細かく数式を展開しており、転載が面倒なため画像で張り付けることとする。



余談:正規分布と偏差値
正規分布や標準偏差を使う計算で最も身近なものは偏差値やIQテストでしょうか。
例えば偏差値は標準偏差を10、平均を50として計算しています。
確率を計算すると、下表のようになります。

つまり、例えば偏差値70を超える人は片側の+2σなので上位約2.3%に入る頭の良さです。